Wealth and Democracy: Plotting, Part 2#
In these expercises, we will be working with country-year level data from the World Development Indicators (published by the World Bank) to understand the relationship between wealth and democratic institutions.
This WDI data includes both countries’ GDP per capita (a measure of wealth) and Polity IV scores (a measure of how democratic a country is – countries with higher scores are liberal democracies countries with low scores are autocratic).
Note by “liberal,” we mean reflecting the values of traditional liberalism with a small-l, not Liberal in the sense of being associated with the US Democratic party.
Exercise 1#
Load the World Development Indicator data from here.
Exercise 2#
Let’s begin analyzing this data by estimating a simple linear model (“ordinary least squares”) of the relationship between democracy scores (polityIV) and GDP per capita (gdppcap08). Polity Scores are the outcome we care about, so make it the dependent variable in your model. We will do so using the statsmodel package, which we’ll discuss in detail later is this course. For the moment, just use this code:
import statsmodels.formula.api as smf
results = smf.ols('polityIV ~ gdppcap08',
data=wdi).fit()
print(results.summary())
Exercise 3#
Based on the results of this analysis, what would you conclude about the relationship between gdppcap08 and polityIV?
Write down your conclusions.
Exercise 4#
Now let’s plot the relationship you just estimated statistically. First, use seaborn.objects to create a scatter plot of polityIV and gdppcap08. Include a title and label your axes (with formatted words, not variable names).
Exercise 5#
Now overlay a linear regression (not a higher order polynomial, just linear) fit to the scatter plot.
Note: linear regression is not symmetric — regressing Polity IV on GDP per Capita does not give the same result as regressing GDP per Capita on Polity IV. That’s because linear regression is designed to minimize the sum of squared errors between predicted values of the y-variable and the true values of the y-variable, so the y-variable is, in a sense, privileged.
Given that, for consistency be sure you make your plot reflect the regression you ran above.
Exercise 6#
Does it seem like the linear model you estimated fits the data well?
Exercise 7#
Linear models impose a very strict functional form on the model they use: they try to draw a straight line through the data, no matter what.
Can you think of a (mathematical) transformation for your data that would make the data a little more sane?
Apply the transformation.
Exercise 8#
Once you’ve applied that transformation, let’s re-fit our model.
Has you sense of the relationship changed at all?
Exercise 9#
When unsure of the most appropriate functional form for a model, it can be useful to fit a non-parametric model — one that does not impose a functional form as strictly.
Fit a lowess regression with confidence intervals using the seaborn_objects_recipes package.
frac is a keyword that manages how much lowess will smooth it’s estimates across the data — higher values will be more smoothed, lower values with fit the data much tighter. Play with the values till you find something you think feels informative.
Exercise 10#
This does seem to fit the data better, but there seem to be quite a few outliers in the bottom right. Who is that? Add text labels to the points on your graph with country names.
Make sure the size of your text labels leaves them legible. There are enough points you won’t be able to perfectly see all labels, but do your best.
You can also add so.Jitter() to “jitter” the location of labels (move them randomly so when several points share an exact coordinate, they’ll be shifted a little).
Exercise 11#
Interesting. It seems that there’s are a lot of rich, undemocratic countries that all have something in common: they’re oil-rich, small, Middle Eastern countries.
Let’s see what happens if we exclude the ten countries with the highest per-capita oil production from our data: Qatar, Kuwait, Equatorial Guinea, United Arab Emirates, Norway, Saudi Arabia, Libya, Oman, Gabon, and Angola. (Note this was in 2007, and excludes very small countries!)
What does the relationship between Polity and GDP per capita look like for non-natural resource producers?
Exercise 12#
Let’s make sure that you accurately identified all 10 of the oil producers. Write a line of code to count up how many big producers you have identified. If you do not get 10, can you figure out what you did wrong?
Exercise 13#
How does the relationship between GDP per capita and Polity look for the oil producers we dropped above?
(Note you can’t add a confidence interval given there are only 10 observations here, so drop the CIs)
Exercise 12#
Look back to your answer for Exercise 2. Do you still believe the result of your linear model? What did you learn from plotting. Write down your answers with your partner.
Exercise 13#
Finally, let’s make a plot that color codes countries by whether they are big oil producers. Include separate linear regression fits for both groups.
Take-aways#
One of our main jobs as data scientists is to summarize data. In fact, its such an obvious part of our jobs we often don’t think about it very much. In reality, however, this is one of the most difficult things we do.
Summarization means taking rich, complex data and trying to tell readers about what is going on in that data using simple statistics. In the process of summarization, therefore, we must necessarily throw away much of the richness of the original data. When done well, this simplification makes data easier to understand, but only if we throw away the right data. You can always calulate the average value of a variable, or fit a linear model, but whether doing so generates a summary statistic that properly represents the essence of the data being studied depends on the data itself.
Plotting is one fo the best tools we have as data scientists for evaluating whether we are throwing away the right data. As we learned from Part 1 of this exercise, just looking at means and standard deviations can mask tremendous variation. Each of our example datasets looked the same when we examined our summary statistics, but they were all radically different when plotted.
Similarly, a simple linear model would “tell” us that if GDP per capita increases by $10,000, we would expect Polity scores to increase by about 1 (i.e. the coefficent on the linear model was 9.602e-05). But when we plot the data, not only can we that the data is definitely not linear (and so that slope doesn’t really mean anything), but we can also see that oil producing countries seem to defy the overall trend, and so should maybe be studied separately.
Moreover, we can see that if we just look at oil producers, there is no clear story: some are rich and democratic, while others are rich and autocratic (indeed, this observation is the foundation of some great research on the political consequences of resource wealth!)
So remember this: tools for summarizing data will always give you an answer, but it’s up to you as a data scientist to make sure that the summaries you pass on to other people properly represent the data you’re using. And there is perhaps no better way to do this than with plotting!
Overlaying Data Series with matplotlib#
In our last plotting exercises, you were asked to make a paired plot in which different data series were plotted next to one another with a shared x-axis. Presumably that resulted in a figure that looked something like this:
import pandas as pd
import numpy as np
import seaborn.objects as so
import seaborn_objects_recipes as sor
from matplotlib import style
import matplotlib.pyplot as plt
import warnings
warnings.simplefilter(action="ignore", category=FutureWarning)
nick_theme = {**style.library["seaborn-v0_8-whitegrid"]}
nick_theme.update({"font.sans-serif": ["Fira Sans", "Arial", "sans-serif"]})
pd.set_option("mode.copy_on_write", True)
wdi = pd.read_csv(
"https://raw.githubusercontent.com/nickeubank/"
"practicaldatascience/master/Example_Data/wdi_plotting.csv"
)
india = wdi[wdi["Country Name"] == "India"]
india = india.rename(
columns={
"CO2 emissions (metric tons per capita)": "Metric Tons Per Cap CO2",
"GDP per capita (constant 2010 US$)": "GDP per capita (US$)",
}
)
p = (
so.Plot(
india,
x="Year",
)
.add(so.Dots())
.pair(
y=[
"Metric Tons Per Cap CO2",
"GDP per capita (US$)",
]
)
)
p
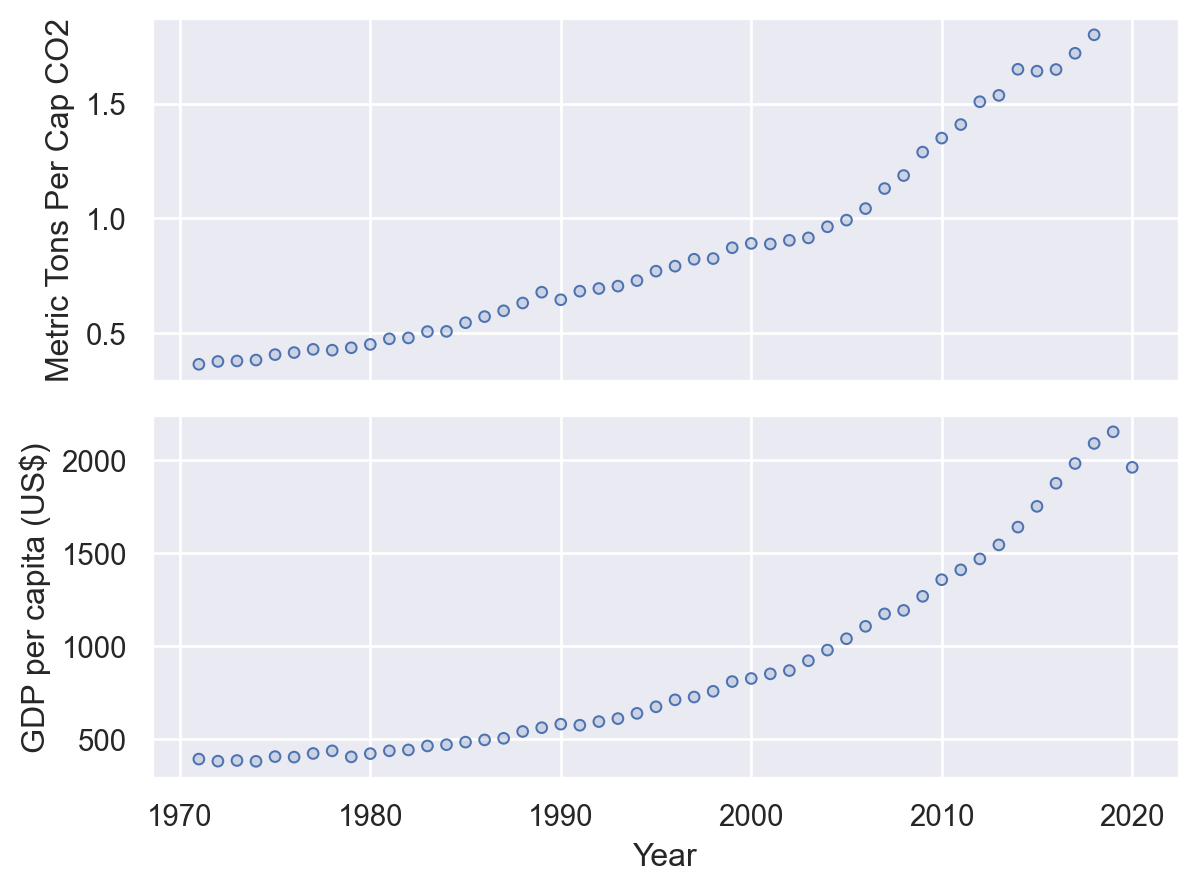
Often times, however, it’s more interesting to directly overlay data series on the same plot to make a figure like this:
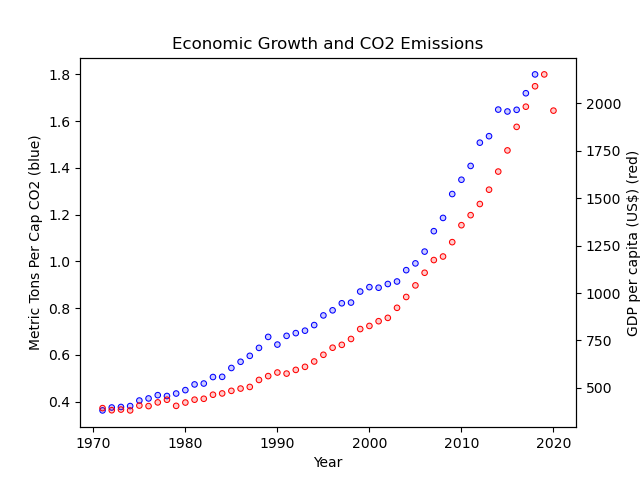
So let’s do that here!
Exercise 14#
Using the data from our last exercise (exercise_plotting_part1), let’s do something like that!
Making this work will require two new tricks:
using the
.twinx()method from matplotlib, andusing the
.on()method from seaborn.objects.
How? Great question! I’m going to leave it to you to figure that out using the documentation for these methods. But here’s a start — you can find the .on() method for seaborn.objects here, and the .twinx() for matplotlib method demonstrated here
Oh, and you may note use these two variables as your two. :)
Good luck!
Also, if you want to, feel free to add any extra bells and whistles as part of your exploration (like a legend, or colored y-axis labels).