Seaborn and the Grammar of Graphics#
Plotting is one of the most important tools of data science, not only for effectively communicating findings to others, but also for exploring and understanding data for oneself. Plotting data allows us to leverage the astounding ability of humans to recognize visual patterns to help us understand data. To do so effectively, however, we need to think carefully about how our visual pattern recognition abilities work, and how we can use that knowledge to effectively present our data.
In this reading, we will learn all about how to make plots using the seaborn plotting library for statistical data visualization. Before we dive into the specifics of the package, however, we need to talk about the philosophy of data visualizations that underlies how it works: the Grammar of Graphics.
The Grammer of Graphics#
The Grammer of Graphics is a framework for thinking about visualization developed by Leland Wilkinson. Its core idea is that any visualization can be decomposed into several constituent parts:
The Data: at the core of any visualization, of course, is the data that were hoping to visualize.
Marks: To visualize our data, we must of course represent the data with actual marks on our figure. These include not only the axes that give our figure form, but also points, circles, bars, or other geometric shapes that populate our figure.
Encoding: Finally, to tie our data to the marks in our figure, we must decide on a mapping from data to marks. This encoding of data into visual features is where the magic happens. In order to represent our data in a figure, we must encode different aspects of our data into the various visual features of our figure. For example, in a simple scatter plot, we encode information about one variable in the location of points along the x-axis, and encode information about another variable in locations along the y-axis. Then in the resulting figure, we would say that we have encoded information about two input variables in the location of points in our figure.
Channels: The visual features of our plot into which we may encode information are called “channels.” Some channels are obvious — in a scatter plot, for example, one channel may be the location of points along the x-axis while another channel is the location of points along the y-axis. But there are other channels into which we can also encode data, like the size, shape, or color of points (e.g. making points larger for, say, more populous countries). Each of these different ways information can be encoded is called a “channel.”
Putting these together, we can say that when we make a figure, we are communicating information about our data by encoding information about the value of different variables in the different channels made possible my our marks.
(To be clear, there are some really interesting nuances to Wilkinson’s work that I can’t do justice to in the space I have here, including discussion of scales, which I’m ignoring for now, but those are the basics!)
This decomposition is especially powerful because it gives rise to a model of graphics that is inherently modular and composable. This is not only helpful when thinking about how to make a good data visualization, but as we will see it is also an obvious foundation for a modular, composable way to specify figures in code. Indeed, it is for this reason that so many popular plotting libraries had been organized around the Grammar of Graphics, including not only the package we will focus on today (seaborn), but also the immensely popular ggplot in R, Altair in Python, Vega in Javascript, and more.
seaborn#
To begin, we have to admit to a small misdirection — in this course we won’t actually be using what some people might think of as seaborn, but rather the relatively new seaborn.objects interface. seaborn has always been a popular Python library for data visualization, but up until late 2022 it did not have a modular, composable, Grammar-of-Graphics inspired interface. Starting with version 0.12 however, seaborn has offered a new interface that we feel is much more powerful.
How seaborn Embodies the Grammar of Graphics#
Before diving into the nuances of seaborn, let’s begin with a simple example to illustrate how the Grammar of Graphics (GoG) manifests in code. In the example below, let’s use a canonical example dataset on penguins (which comes included with seaborn) to examine the relationship between penguin mass and other physical features:
# Import pandas and seaborn.objects
import pandas as pd
import numpy as np
import seaborn.objects as so
pd.set_option("mode.copy_on_write", True)
# Load penguins dataset
import seaborn as sns
penguins = sns.load_dataset("penguins").dropna()
penguins.head()
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
| 5 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | Male |
Let us start by just looking at the relationship between body mass and bill length:
so.Plot(penguins, x="bill_length_mm", y="body_mass_g").add(so.Dot())
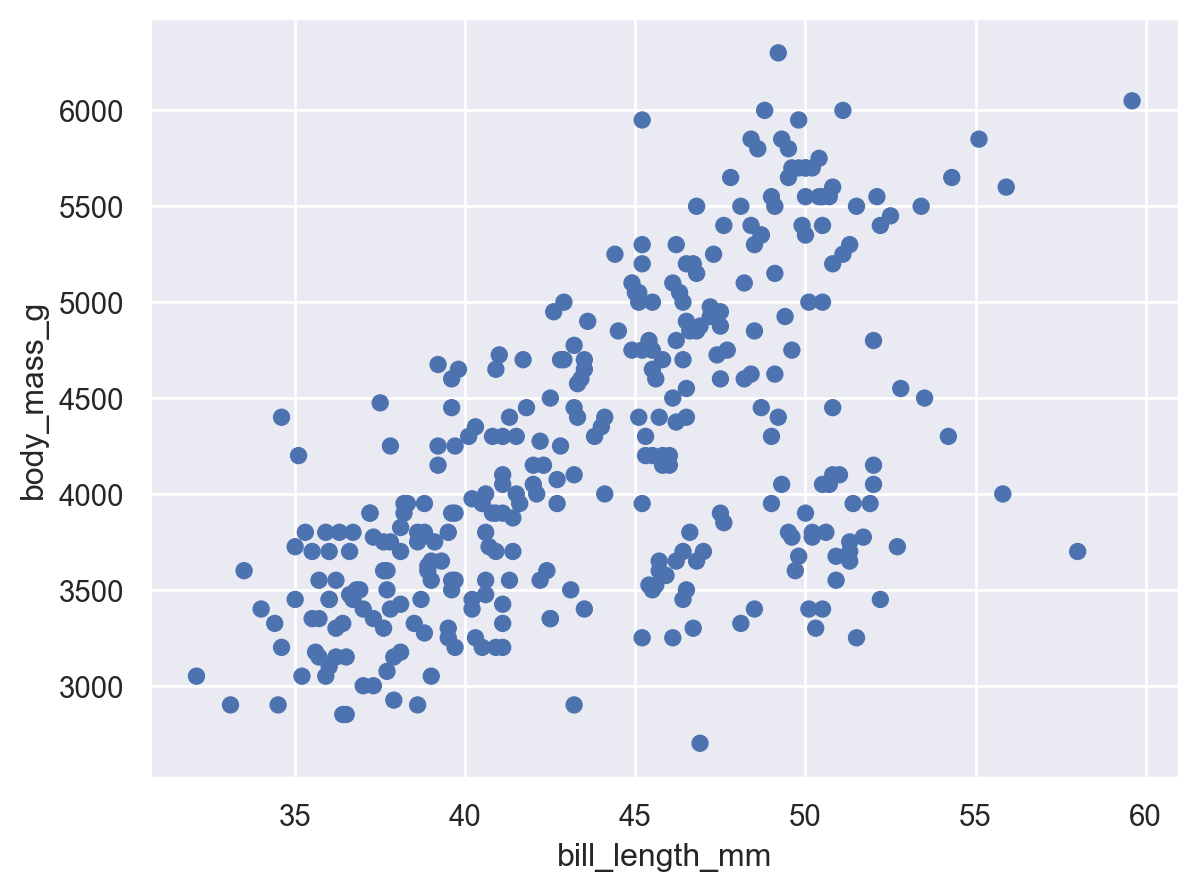
(If you get FutureWarnings when you run this code, don’t worry about it — those are just notes about things that aren’t an issue now that seaborn will need to address internally before bigger changes in libraries it depends on take effect. To filter those out, just add the code I use below in your own code.)
Here, you can see that the first thing we’ve passed is our Data (penguins), we’ve added Dot() as our Marks, and we’ve encoded bill_length_mm into the x-axis location of our points, and body_mass_g into the y-axis location of our points.
As I said before, the most powerful part of a GoG-inspired syntax is that it’s extremely modular. Suppose, looking at this, we notice a strong upward trend through the middle of the data, but also a weird mass in the bottom right. What might that be? Well, let’s go fishing! Let’s encode some additional information in our figure through the channel of dot color:
# Filter out FutureWarnings
import warnings
warnings.simplefilter(action="ignore", category=FutureWarning)
# Add color
so.Plot(penguins, x="bill_length_mm", y="body_mass_g", color="sex").add(so.Dot())
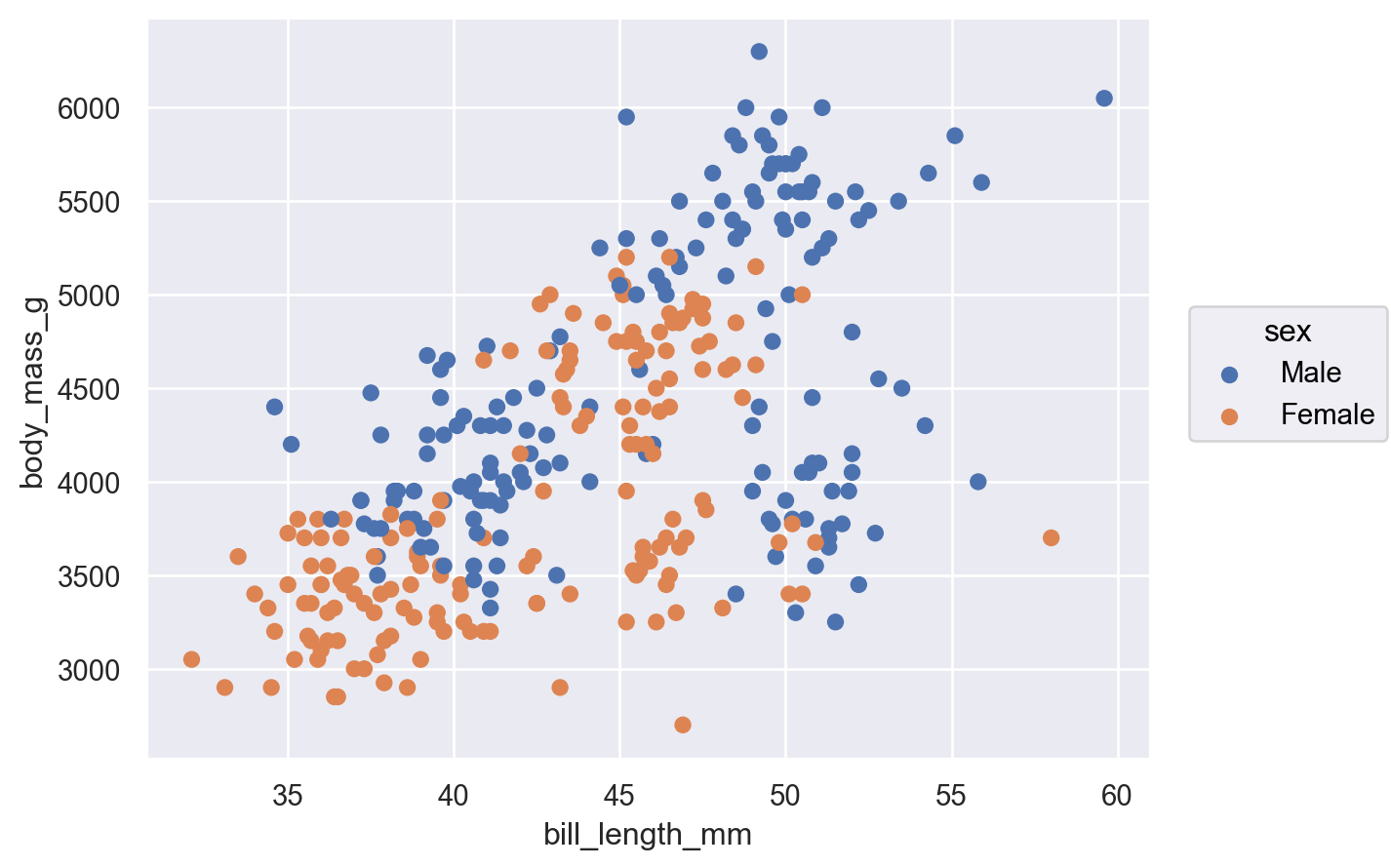
Great! And just like that, we can easily see that while female penguins do tend to be smaller than their male counterparts, that doesn’t explain this weird shape of the data. Slits and code a different variable — species!
so.Plot(penguins, x="bill_length_mm", y="body_mass_g", color="species").add(so.Dot())
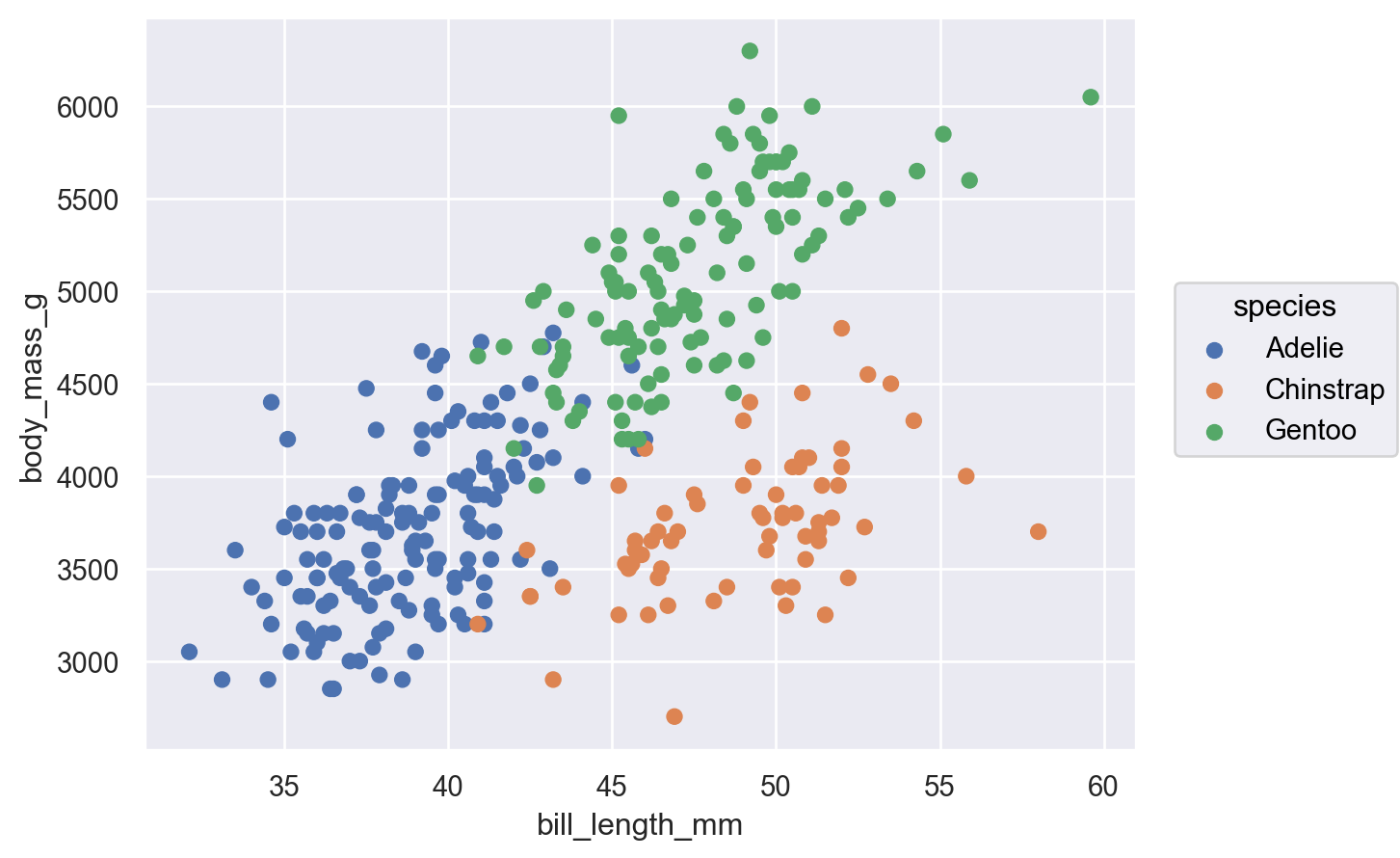
Ah, there we go! That’s clearly what explains much of this shape.
Notice how powerful that was — we were able to think in terms of the features of the data we wanted to understand, and we were able to uncover a pattern relatively quickly that would have been extremely difficult to grok (really understand at an intuitive level) using summary statistics or non-visual data tabulations.
seaborn, GDP per Capita, and Economic Development#
To better demonstrate not only the ins-and-outs of the seaborn plotting library, but also how plotting can be used for exploratory data analysis, let’s take a look at the relationship between average income and different measures of human development.
Among people who are interested in trying to improve living conditions in developing countries around the world, one canonical debate is about whether the best way to help those most in need is to focus on encouraging economic growth writ large, or whether it would make more sense to focus on specific interventions around things like infant mortality or the education of girls.
Many economists argue that encouraging economic growth may actually be the most efficient way of achieving improvements in human development not because economic growth itself is intrinsically valuable, but because economic growth tends to be associated with improvements in lots of other things that we care about, presumably because a better functioning economy and wealthier citizens are better able to build the institutions and public service delivery systems necessary to provide access to schools and public health everyone.
Others argue that efforts to encourage economic growth are targeting an outcome that we don’t actually care about (income) rather than targeting the things that we are actually trying to encourage (higher life expectancy, equal access to education, etc.). In this view, targeting the specific outcomes is much more likely to help us achieve the things that we care about most.
(Of course, it’s worth emphasizing that this way of framing the debate is simplistic – this is not an either/or proposition, and efforts can be directed in both directions. But in a world of scarce resources, practitioners do sometimes have to decide whether they allocate resources to encouraging economic growth through, say, small business loans versus putting money into building schools.)
In an effort to move beyond debating this in the abstract, in this lesson we will use Altair to look at patterns between economic growth (measured in terms of average incomes in different countries, measured as Gross Domestic Product (GDP) per capita) and other development outcomes (life expectancy, literacy, etc.). We will be doing so using data from the World Development Indicators (WDI) database from the World Bank that provides country-level data on a range of outcomes.
Loading WDI Data#
The data we’ll be using can be found here. This is basically straight from the WDI website, though I’ve made a couple small formatting changes to make life a little easier.
Let’s begin by loading the data and getting a quick sense of what we have:
wdi_data = (
"https://raw.githubusercontent.com/nickeubank/"
"practicaldatascience/master/Example_Data/wdi_plotting.csv"
)
world = pd.read_csv(wdi_data)
world.sample(5)
| Year | Country Name | Country Code | GDP per capita (constant 2010 US$) | Population, total | CO2 emissions (metric tons per capita) | Mortality rate attributed to household and ambient air pollution, age-standardized (per 100,000 population) | PM2.5 air pollution, population exposed to levels exceeding WHO guideline value (% of total) | Life expectancy at birth, total (years) | Mortality rate, under-5 (per 1,000 live births) | Literacy rate, youth female (% of females ages 15-24) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 6345 | 2000 | Czech Republic | CZE | 14889.069920 | 10255063.0 | 12.010653 | NaN | 99.967352 | 74.968293 | 5.5 | NaN |
| 10604 | 2019 | Switzerland | CHE | 83093.185220 | 8575280.0 | NaN | NaN | NaN | 83.704878 | 4.0 | NaN |
| 6032 | 1998 | Slovak Republic | SVK | 10209.056010 | 5390516.0 | 7.680155 | NaN | NaN | 72.551220 | 10.6 | NaN |
| 1449 | 1977 | Norway | NOR | 43236.988840 | 4043205.0 | 7.684619 | NaN | NaN | 75.386829 | 11.5 | NaN |
| 1561 | 1978 | Colombia | COL | 3746.390955 | 25733669.0 | 1.619776 | NaN | NaN | 65.964000 | 65.5 | NaN |
We can also look at the columns in the dataset a little more systematically:
for c in world.columns:
print(c)
Year
Country Name
Country Code
GDP per capita (constant 2010 US$)
Population, total
CO2 emissions (metric tons per capita)
Mortality rate attributed to household and ambient air pollution, age-standardized (per 100,000 population)
PM2.5 air pollution, population exposed to levels exceeding WHO guideline value (% of total)
Life expectancy at birth, total (years)
Mortality rate, under-5 (per 1,000 live births)
Literacy rate, youth female (% of females ages 15-24)
And finally, we can look at the years that are included in the data:,
world.Year.describe()
count 10850.000000
mean 1995.500000
std 14.431535
min 1971.000000
25% 1983.000000
50% 1995.500000
75% 2008.000000
max 2020.000000
Name: Year, dtype: float64
And the number of countries (although we can already see from the sample above that not all countries have all variables defined in every year):
# How many countries?
world["Country Name"].nunique()
217
Basic Descriptive Plotting#
Given our interest in the relationship between average income and human development, let’s start by looking at the relationship GDP per capita and the standard measure of the quality of public health in a country: the mortality rate for young children.
To start, let’s also limit our attention to data from a single year – we can look at variation over time later.
world = world[world.Year == 2018]
(
so.Plot(
world,
x="GDP per capita (constant 2010 US$)",
y="Mortality rate, under-5 (per 1,000 live births)",
).add(so.Dot())
)
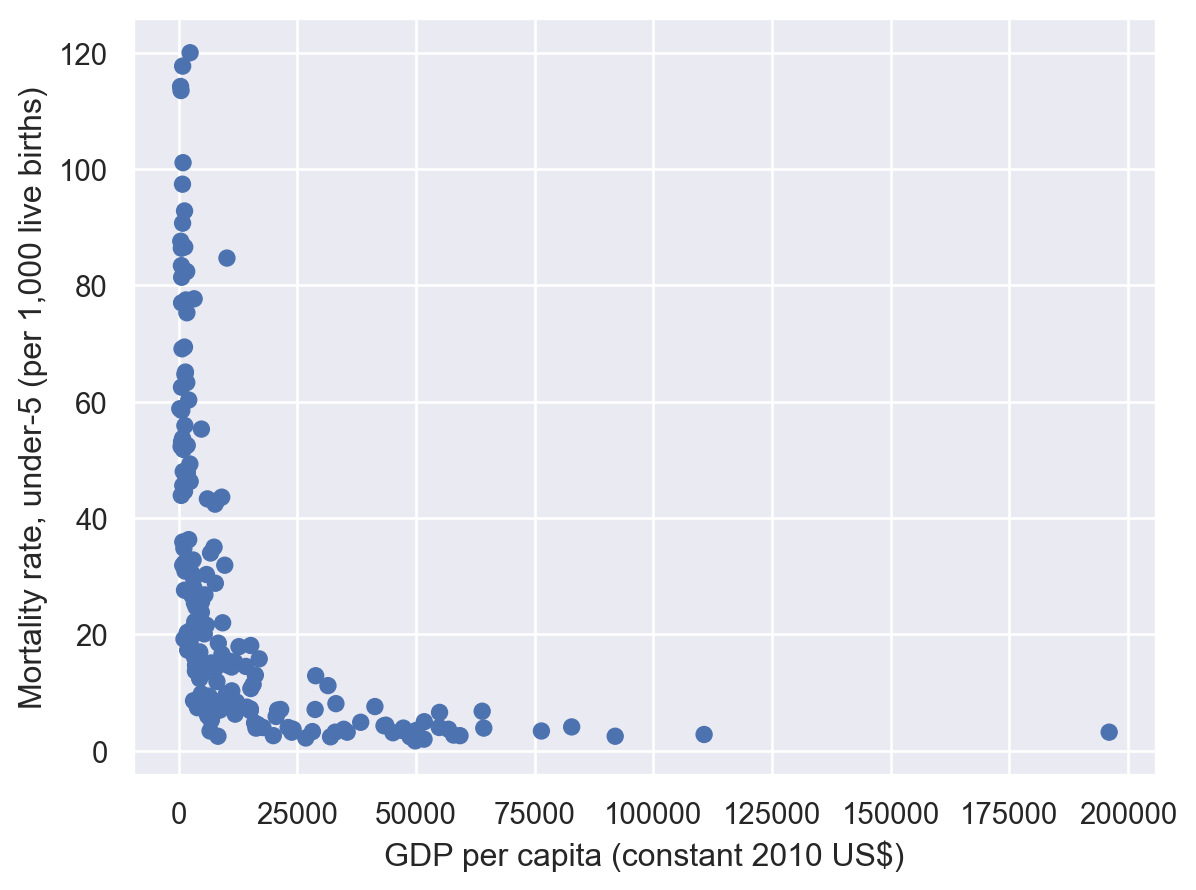
Here we immediately see one of the great things about plotting – we can instantly recognize that this relationship is not remotely linear, which is important to know because it means any analysis designed to measure linear relationships (like a simple correlation or a linear regression) would be misleading. Moreover, not only do we see it’s non-linear, but we can get a sense of the way in which it’s non-linear!
(Yes, there are ways to learn this without plotting, but those approaches tend not to tell us what functional form the relationship actually takes, and can often be fooled by certain non-linear relationships in a way your eye is not! Indeed, even the standard way of validating the linearity assumption in a linear regression is to plot your residuals for this precisely reason.)
So let’s log our variables to get something more linear and easy to interprete:
world["log_gdp_per_cap"] = np.log(world["GDP per capita (constant 2010 US$)"])
world["log_under5_mortality_rate"] = np.log(
world["Mortality rate, under-5 (per 1,000 live births)"]
)
(
so.Plot(
world,
x="log_gdp_per_cap",
y="log_under5_mortality_rate",
).add(so.Dot())
)
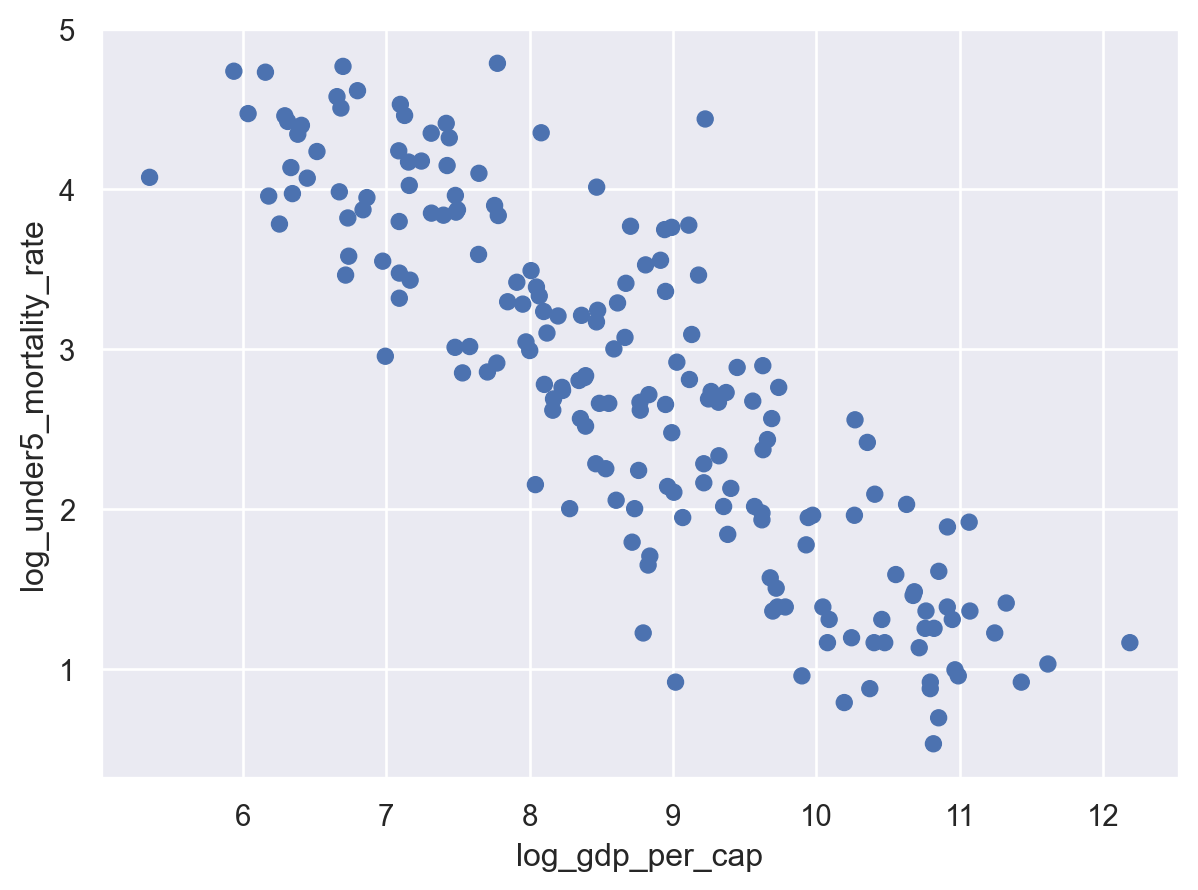
Much better. Here we can clearly see a nice, linear relationship between logged GDP per capita and logged child mortality.
However, the plot is a little crowded. To get points that are a little easier to read when you have a lot of overlapping data (your plot is a little overplotted), you can use so.Dots() instead of so.Dot() as your mark:
(
so.Plot(
world,
x="log_gdp_per_cap",
y="log_under5_mortality_rate",
).add(so.Dots())
)
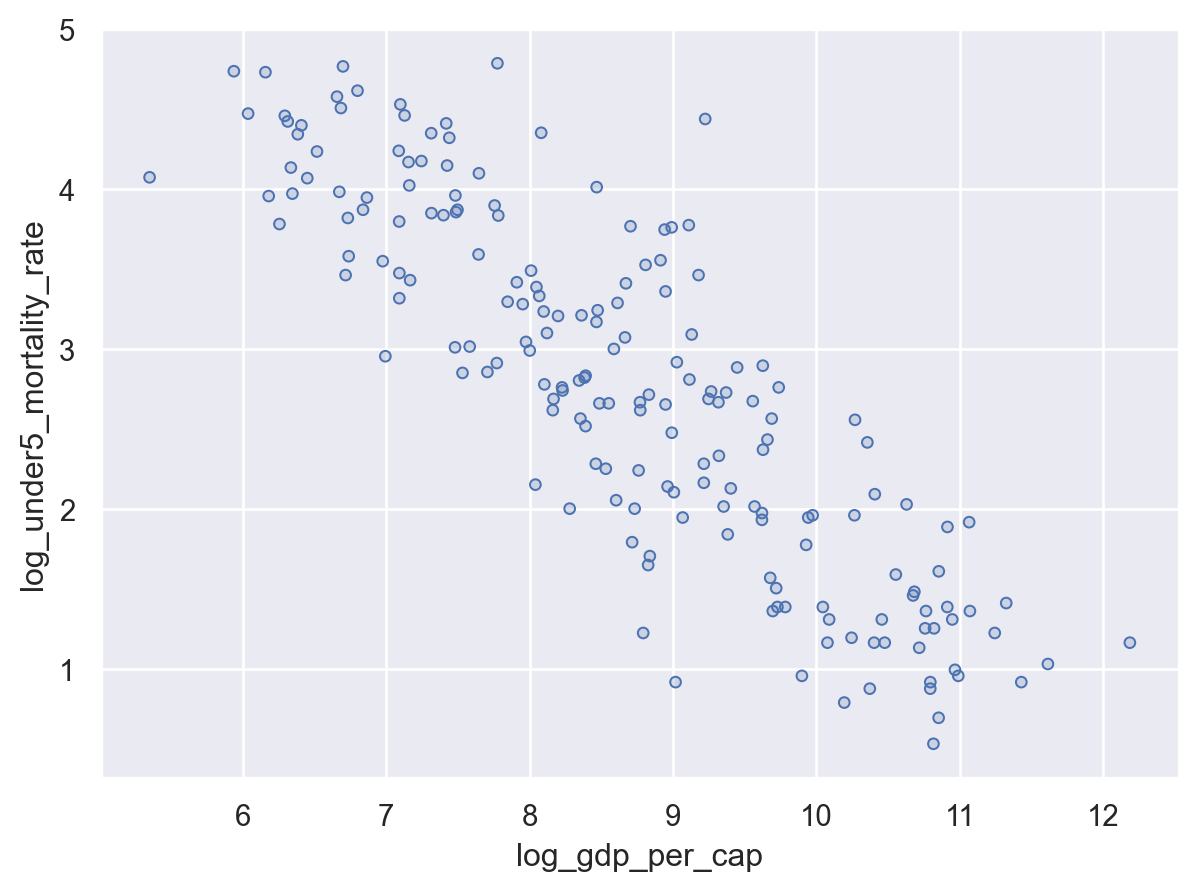
Adding More Channels#
So far we’ve made great progress on the question we were asking: does average income seem to be strongly correlated with childhood morality? Yes, they are clearly strongly correlated, though with some dispersion of outcomes at each income level.
But as we saw above, we have more than 200 countries in this dataset, and each country is represented by a single point in that figure. This is equitable, but perhaps misleading – if we’re interested in human welfare, then not all countries are equally important; after all, nearly half of all people alive live in only 7 countries! What if this relationship between childhood mortality is true for small countries, but not big ones, but we can’t see it because all countries are being plotted the same way?
One way to address this is to encode additional data – the population of each country – to another channel. The location of points on x and y axes are, of course, the most obvious encoding channels in a visualization, but they are far from the only ones available! Indeed, Altair allows information to be encoded in a range of mark features, including:
Color
Size
Shape
Stroke (for lines)
Opacity
and more.
So let’s add one of these to our data – let’s encode population in the size of our points, so big countries get bigger points! That way we can see if big countries also seem to be following this trend we see:
(
so.Plot(
world,
x="log_gdp_per_cap",
y="log_under5_mortality_rate",
pointsize="Population, total",
).add(so.Dots())
)
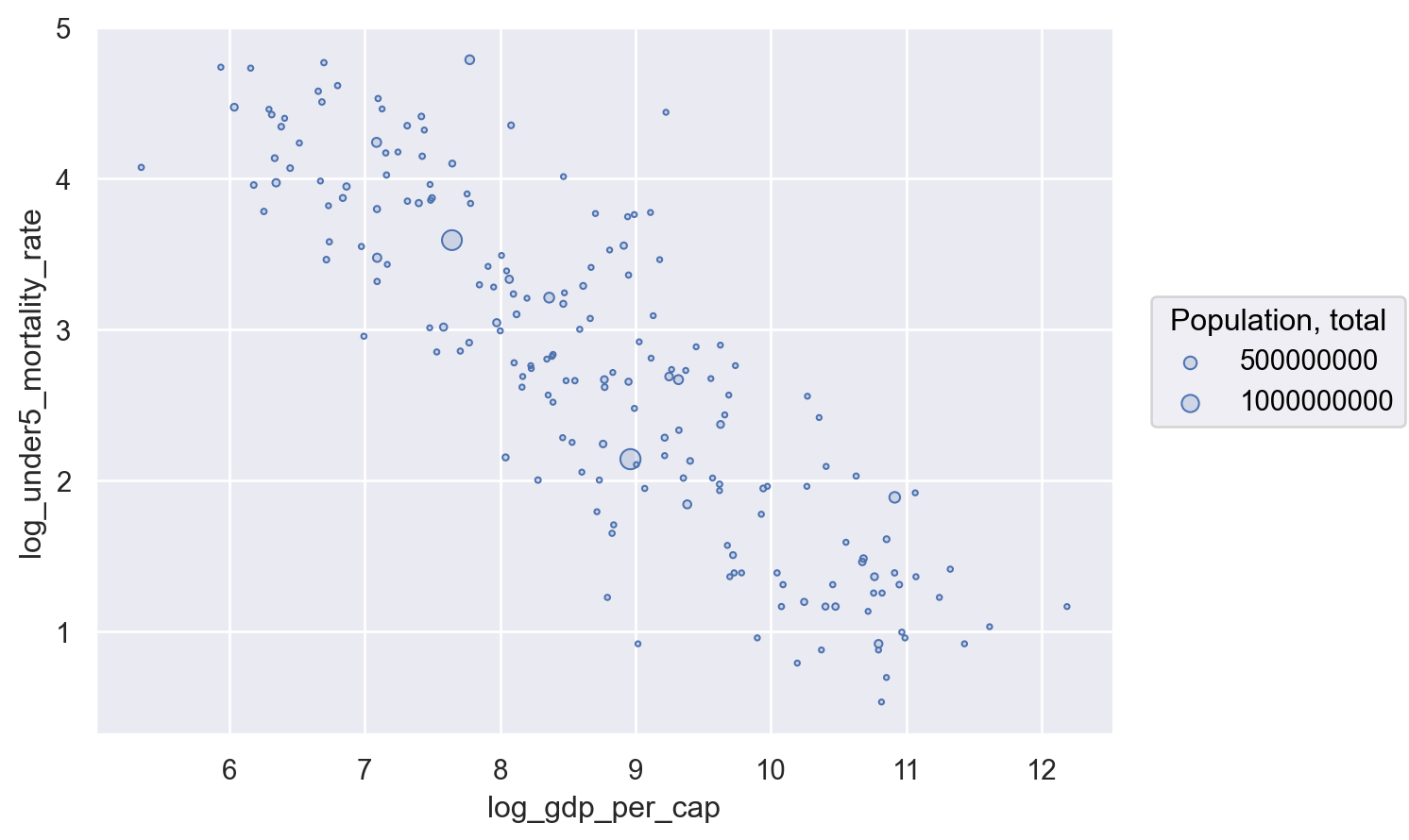
And just like that we have added substantial information to our figure! In this case, what we’ve learned is that the linear relationship we see for all countries is similar to the linear relationship we see if we focus only on big countries (since we see the bigger circles distributed all along the same general line as the smaller points), which should re-assure use that the relationship we see holds both for the average country and for the average person.
The Encoding Channel Hierarchy#
In the figure above, we encoded GDP per capita to each point’s x-axis location, Mortality to each point’s y-axis location, and population to point size. But why are encoding GDP and Mortality to x-y locations, and population to size? We could have just as easily encoded population in x-axis locations, and GDP in size:
world["log_population"] = np.log(world["Population, total"])
(
so.Plot(
world,
x="log_population",
y="log_under5_mortality_rate",
pointsize="log_gdp_per_cap",
).add(so.Dots())
)
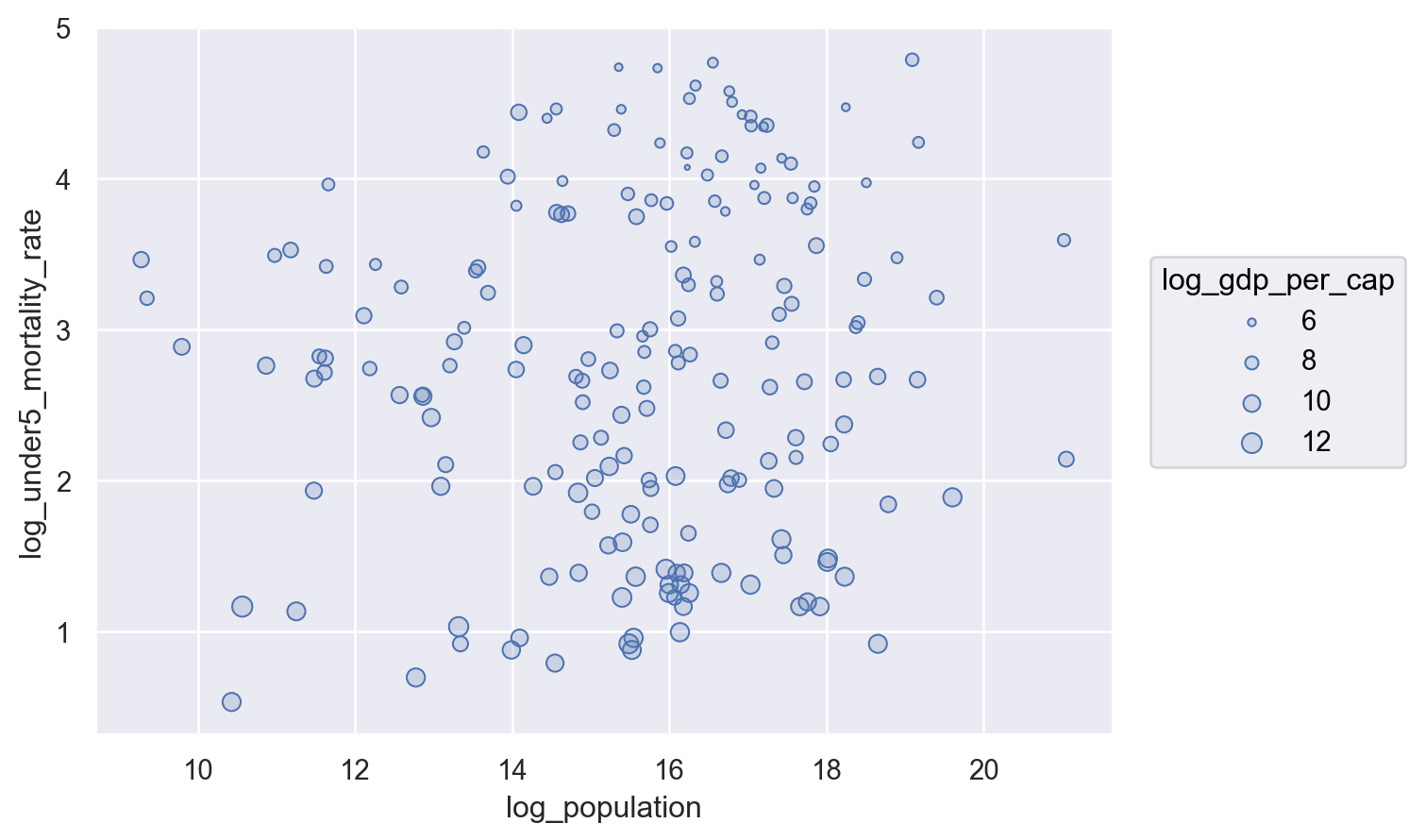
But when we look at that figure, we immediately get the sense we’ve done something wrong. Why?
The answer is that not all encoding channels are created equal. Our visual pattern recognition system is more sensitive to some channels (like x-y locations) than others (size). In the figure above, for example, the pattern between GDP and Mortality is still present, the problem is that it manifests as the marks being ever so slightly larger at the bottom of the figure than at a top, a difference that’s really hard to see.
(Why is this the case? While it’s always dangerous to play armchair evolutionary biologist, it’s not hard to imagine a reason we are so sensitive to location. Misperceive the location of an object even a little and your spear throw goes awry, or you foot misses the rock you were trying to step on. Misperceive the size of an apple a little and… well, there are probably no consequences!)
This idea of a hierarchy of encoding channels is explored in detail in Jacques Berin’s Semiology of Graphics. As with the Grammer of Graphnics, I won’t go into all of the thoughtful nuance from the original book, but in short Jacques argues that the top of the channel hierarchy is (in decreasing order of desirability):
Position
Size
Color
Shape
(There are all sorts of nuance for data that’s categorical versus cardinal, and different rules for points versus lines versus shapes, but crucially in all cases position is at the top!)
And that’s why this figure seems so wrong – we haven’t used position to encode the relationship we care about most, but instead used a mixture of position (for Mortality) and size (for GDP per capita), obscuring what we most want to understand.
In our original figure, by contrast, we encoded a secondary variable of interest (population) into a secondary channel (size). And given we only wanted to quickly see if the relationship we were seeing was a relationship that was true for both large and small countries, this secondary channel was sufficient. But it’s not sufficient for GDP per capita.
Layering#
One feature of this plot is that we see a significant relationship between GDP per capita and child mortality, but we also see that there is some dispersion of outcomes around that trend – even at the same income level, some countries are outperforming others in terms of reducing child mortality.
To make this easier to visualize, it may be helpful to add a line-of-best-fit (e.g. a linear regression line) to our plot — something that seaborn (as a statistical data visualization library) makes very easy!
First, we need to recognize that we’re trying to add a new Mark to our figure — in this case, a line. We do this by adding .add(so.Line()) to the end of our current plot. Then, helpfully, we just have to tell seaborn that we want that line to be a linear fit to the data by adding so.PolyFit() inside that .add() statement.
(
so.Plot(
world,
x="log_gdp_per_cap",
y="log_under5_mortality_rate",
)
.add(so.Dots())
.add(so.Line(), so.PolyFit())
)
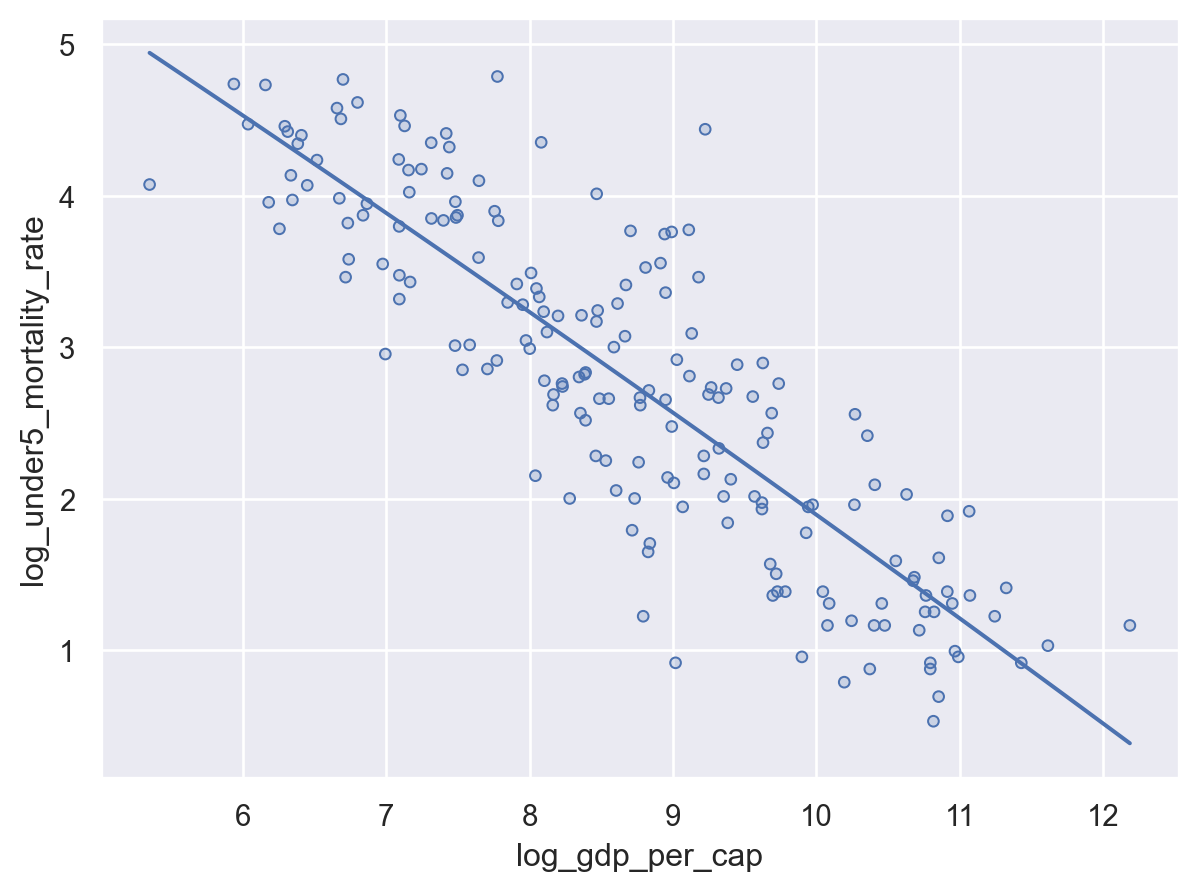
Note that by default, PolyFit() will fit a second-order polynomial (though you can’t really see that here, as the best fit is quite linear!). If you just want a linear fit, you can specify that with so.PolyFit(order=1).
Layer-Specific Encodings#
On nuance to encodings with multiple marks is that one must be careful about how one specifies an encoding, as encodings specified in different ways will apply either to all marks, or only to one mark.
Basically, if you specify an encoding in Plot(), it will apply to all Marks. If, by contrast, you add an encoding inside a specific Mark’s add() method, it will only apply to that Mark. And if you want to just modify a Mark (not by encoding it to a variable, but just change a setting), you put that change in the Mark itself (e.g., so.Dots(markersize=10)).
Here’s a great visual from the seaborn documentation on this point (they use the term “mapped” instead of “encoded”):

Warning
If you add an encoding inside Plot() that isn’t supported by some of your layers, those layers will just disappear.
To illustrate this weird behavior, let’s re-insert pointsize="Population, total" into our Plot() statement. pointsize doesn’t mean anything to a so.Line() mark, so that layer will just… vanish.
(
so.Plot(
world,
x="log_gdp_per_cap",
y="log_under5_mortality_rate",
pointsize="Population, total",
)
.add(so.Dots())
.add(so.Line(), so.PolyFit())
)
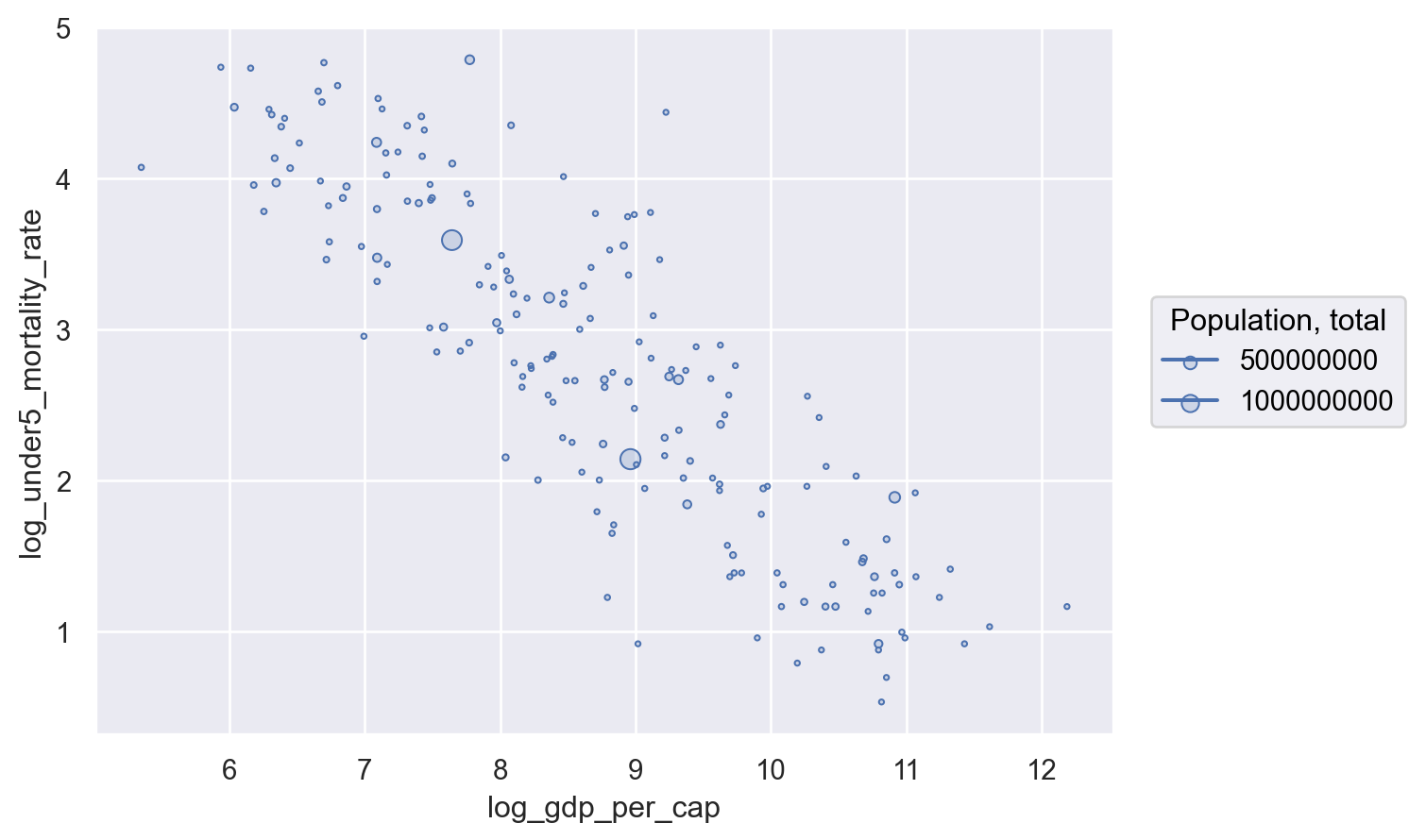
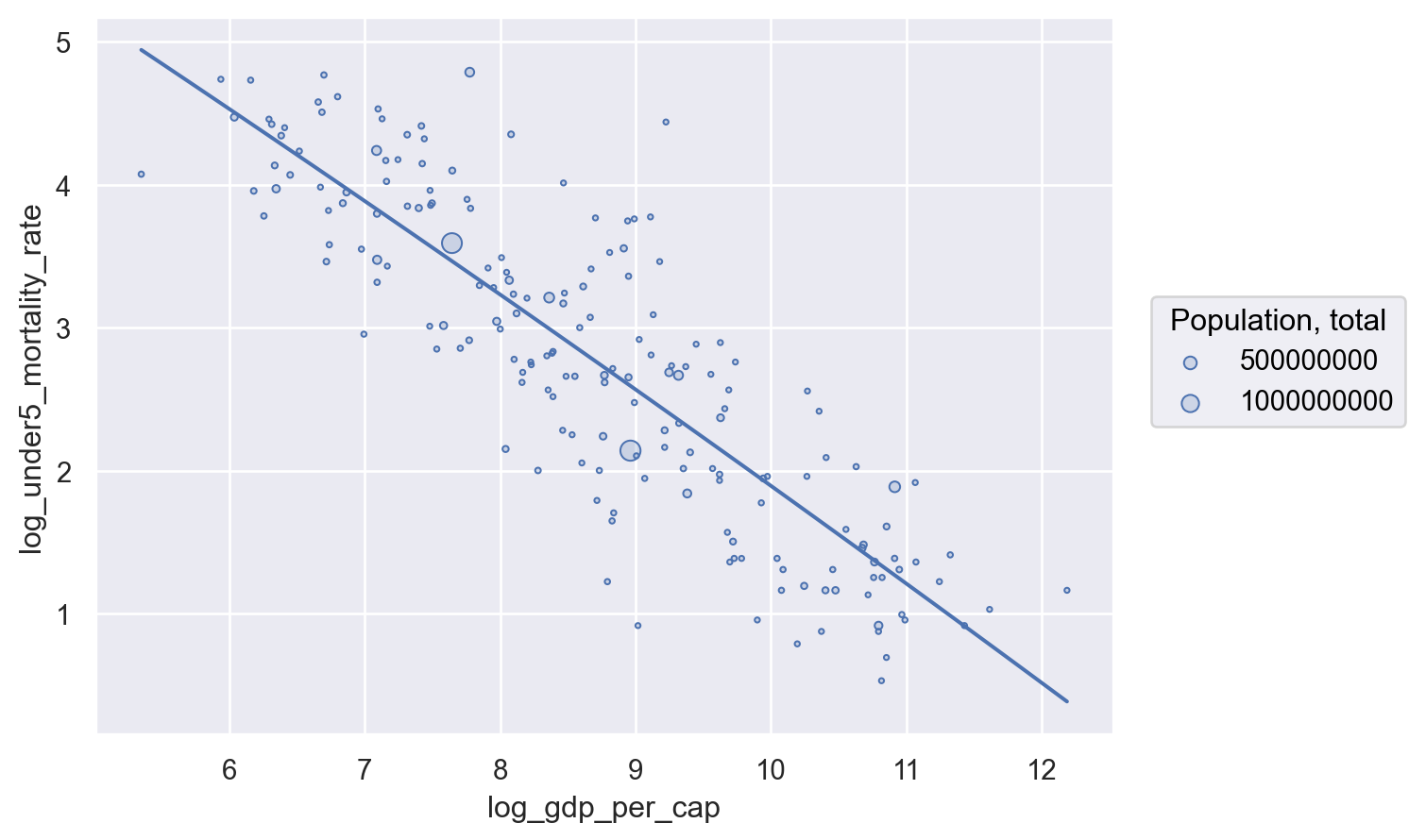
To bring back our regression, we have to move that encoding inside the .add() argument for so.Dots() so it only applies to that layer.
(
so.Plot(
world,
x="log_gdp_per_cap",
y="log_under5_mortality_rate",
)
.add(so.Dots(), pointsize="Population, total")
.add(so.Line(), so.PolyFit())
)
We can also see how this kind of layer-specific specification works through the addition of the names of countries to our plot. This gets pretty busy and this is probably too much on a plot, but it’s the kind of thing that can be useful for data exploration.
First, we want to add a new Mark: so.Text(). And we want to encode into that text "Country Code". Obviously this encoding is specific to this geometry, so we add it in that .add() layer:
(
so.Plot(world, x="log_gdp_per_cap", y="log_under5_mortality_rate")
.add(so.Dots(), pointsize="Population, total")
.add(so.Line(), so.PolyFit())
.add(so.Text(), text="Country Code")
)
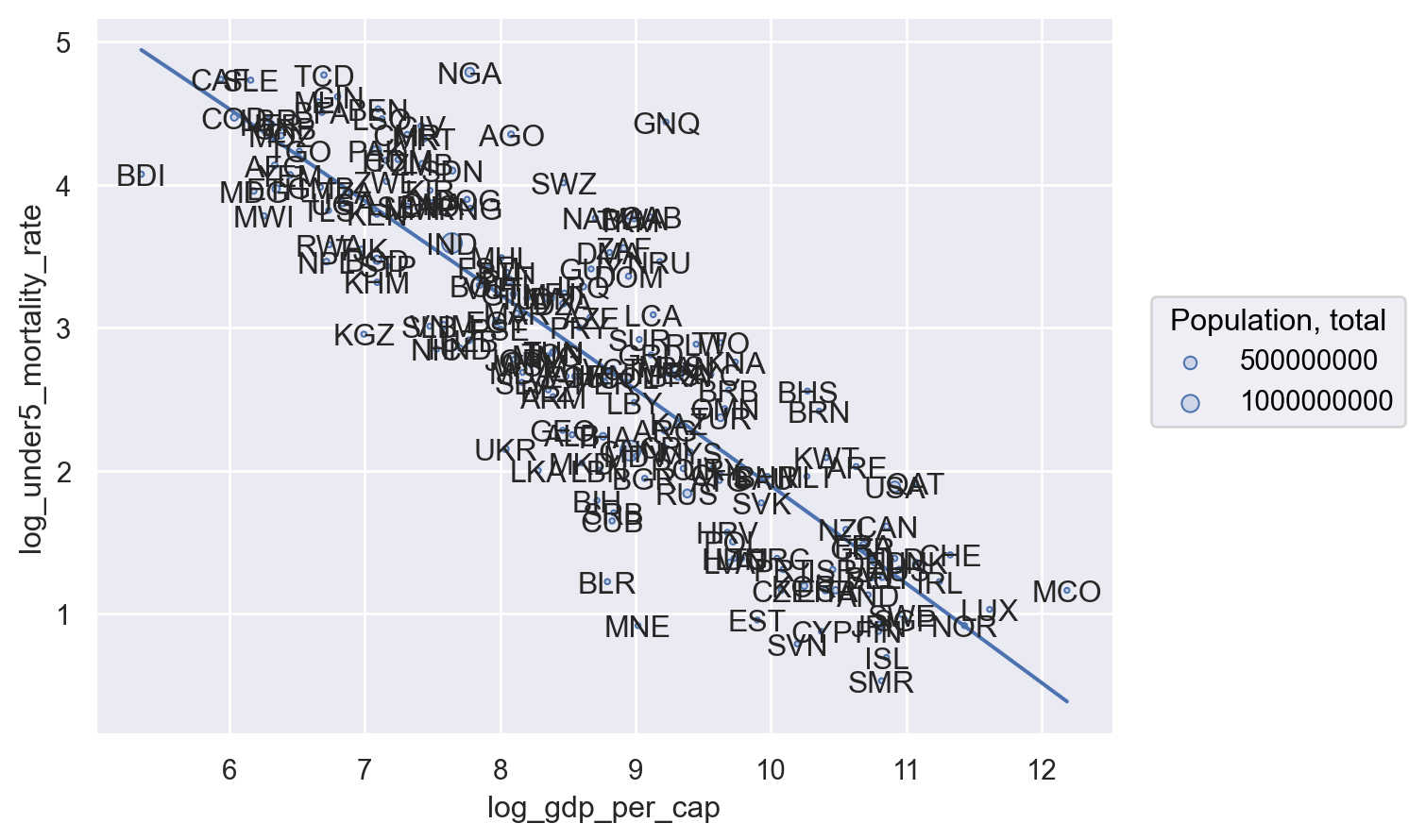
Wow… that’s unreadable. OK, so we need to make our font smaller. How do we do that? We can start by looking at the options for the so.Text() mark by typing so.Text? into Python to see it’s documentation. There we’ll see one argument is fontsize. Great! Since this isn’t encoding — we aren’t trying to link font size to a variable in our data, just modify a setting of the Mark, that option goes in so.Text():
(
so.Plot(world, x="log_gdp_per_cap", y="log_under5_mortality_rate")
.add(so.Dots(), pointsize="Population, total")
.add(so.Line(), so.PolyFit())
.add(so.Text(fontsize=8), text="Country Code")
)
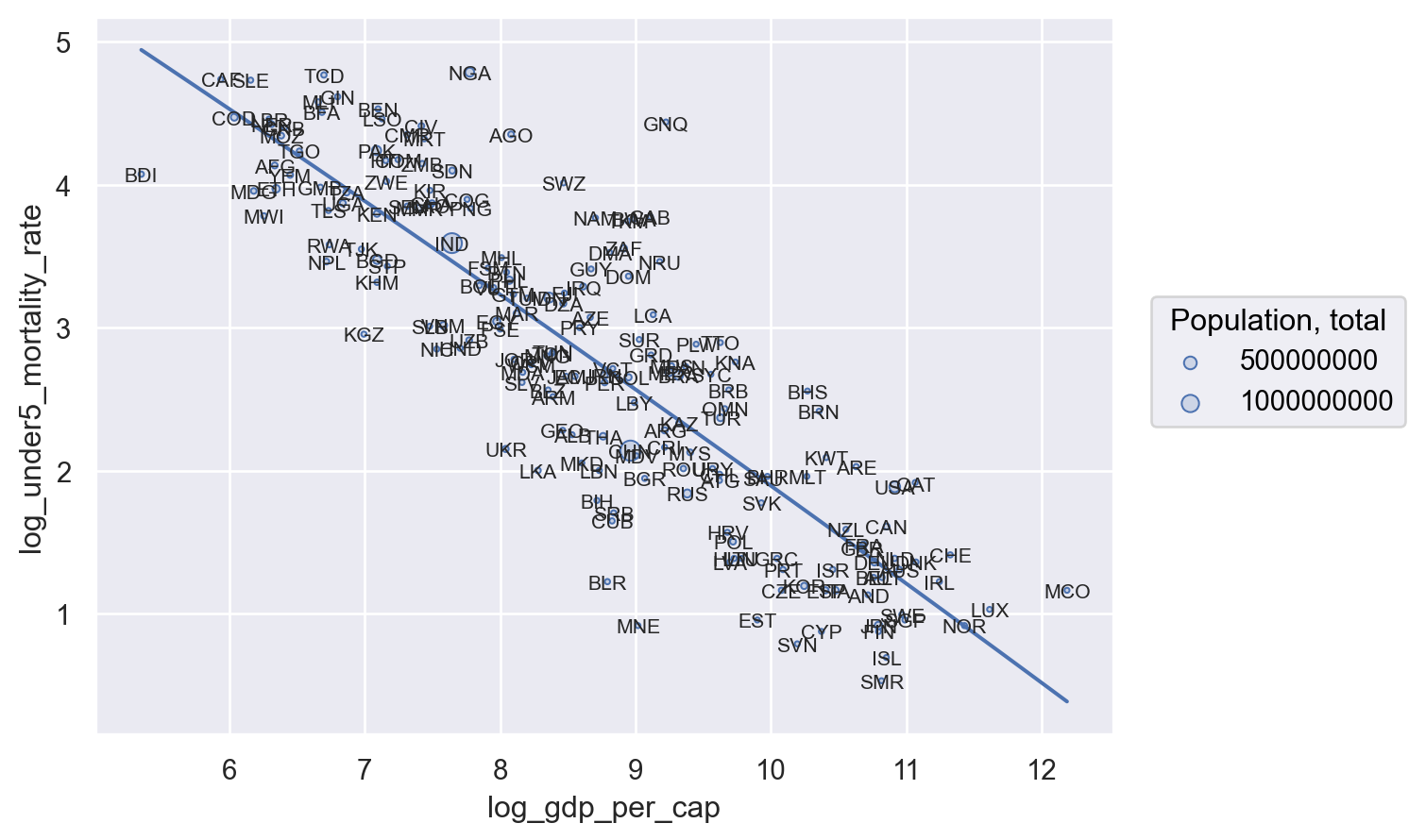
Much better! Still not something I’d put in a paper, but that’s it’s helpful if I wanted to, say, figure out who my outliers were (like Nigeria, NGA).
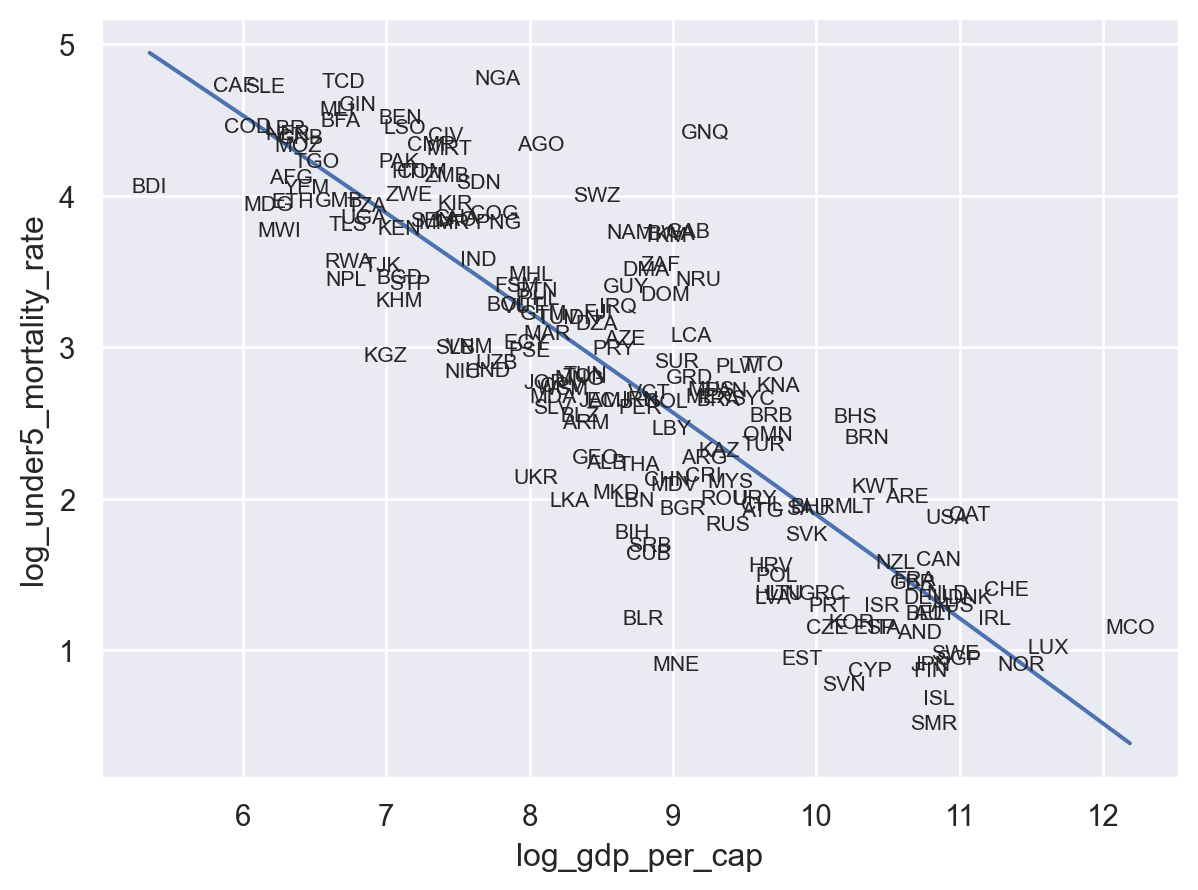
Of course, we might also want to make this more readable by just dropping our Dots and just using text labels.
(
so.Plot(world, x="log_gdp_per_cap", y="log_under5_mortality_rate")
.add(so.Line(), so.PolyFit())
.add(so.Text(fontsize=8), text="Country Code")
)
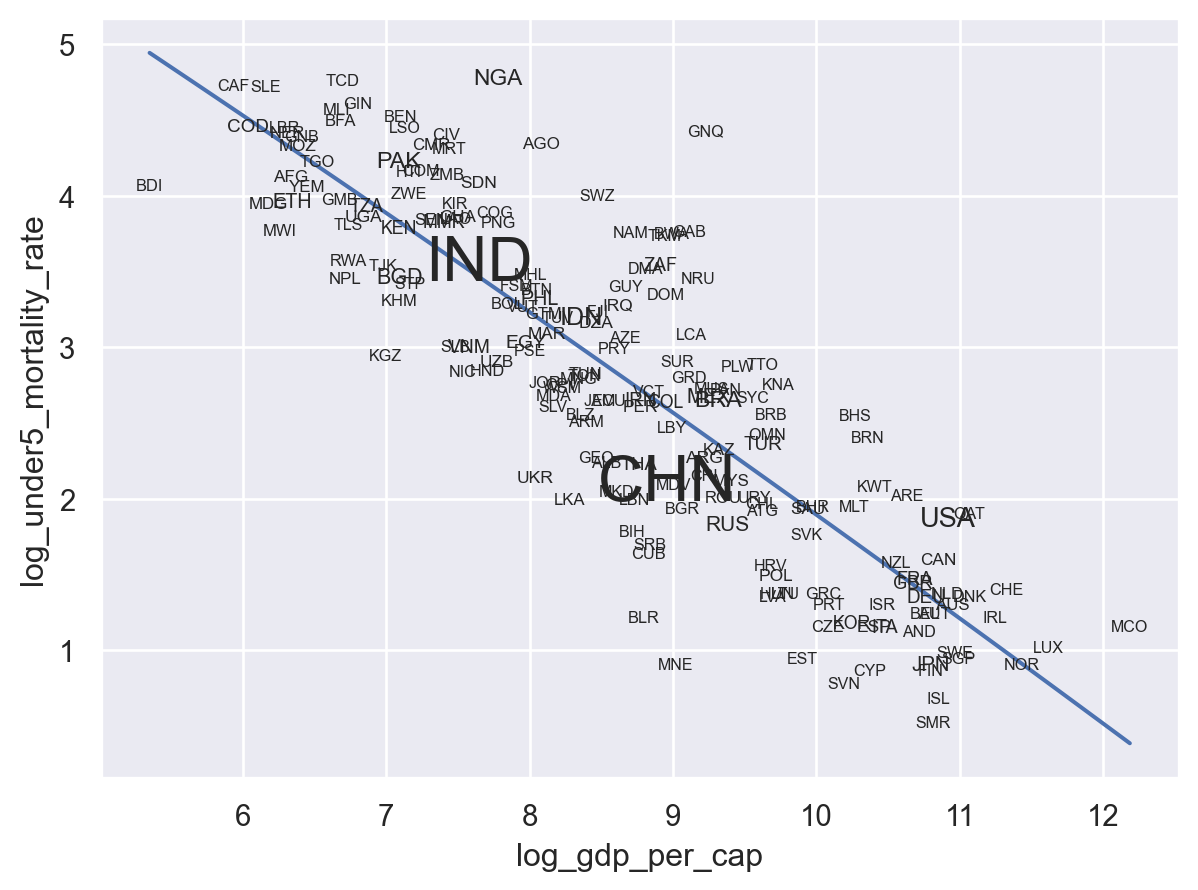
And if we really wanted to be cute, we could even bring back the population encoding by using it to control the fontsize. How? Well, with fontsize="Population, total" of course! But since we’re not changing a setting of the mark but rather adding an encoding, we have to move fontsize from inside so.Text(fontsize=8) to being next to it in the same .add(): .add(so.Text(), text="Country Code", fontsize="Population, total")
(
so.Plot(world, x="log_gdp_per_cap", y="log_under5_mortality_rate")
.add(so.Line(), so.PolyFit())
.add(so.Text(), text="Country Code", fontsize="Population, total")
)
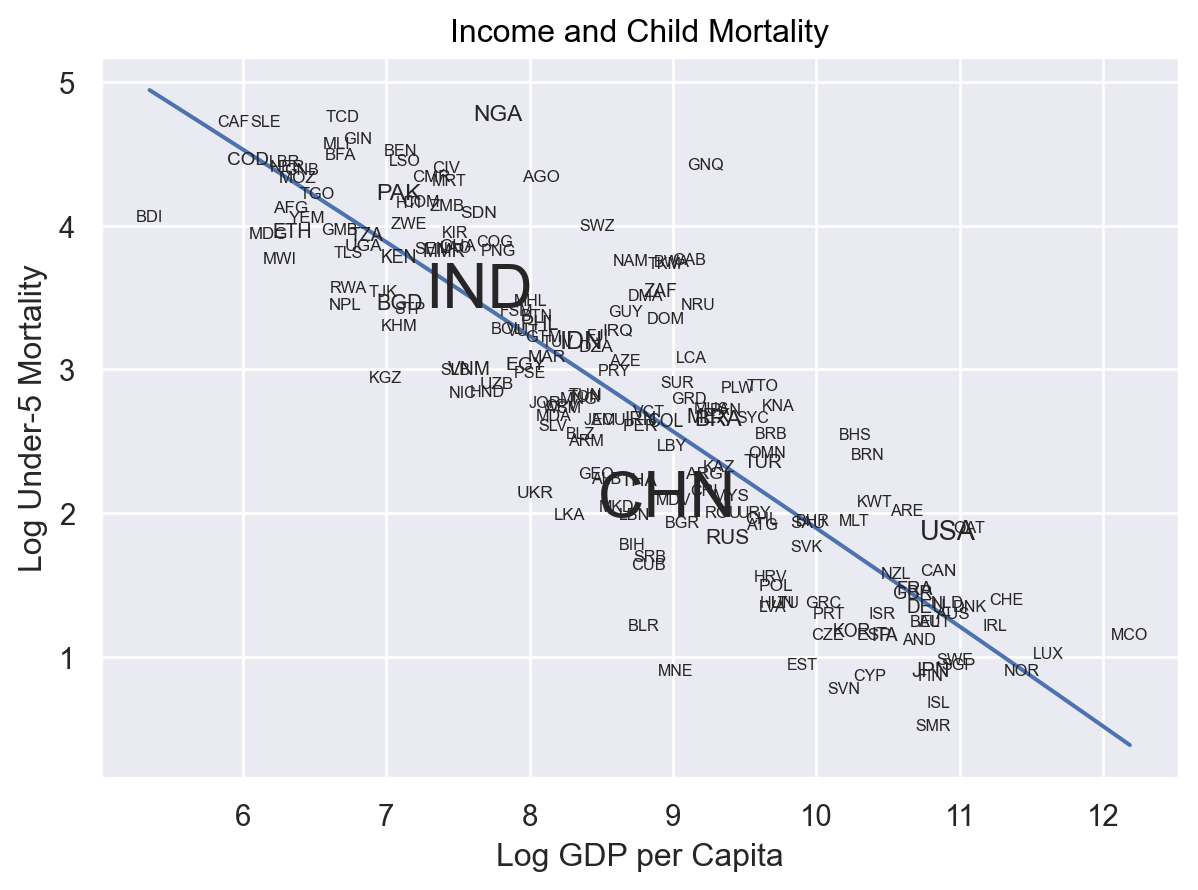
Adding Titles Labelling Axes#
Now suppose you wanted to share what you’d discovered – you’d probably want to clean up your variables names and titles! Thankfully, it’s very easy! Just add .label()
(
so.Plot(world, x="log_gdp_per_cap", y="log_under5_mortality_rate")
.add(so.Line(), so.PolyFit())
.add(so.Text(), text="Country Code", fontsize="Population, total")
.label(
x="Log GDP per Capita",
y="Log Under-5 Mortality",
title="Income and Child Mortality",
)
)
Themes#
Want to customize the look of your plots? Great! You can use any matplotlib theme (here’s a gallery) with the following syntax:
# Import themes
from matplotlib import style
(
so.Plot(world, x="log_gdp_per_cap", y="log_under5_mortality_rate")
.add(so.Line(), so.PolyFit())
.add(so.Text(), text="Country Code", fontsize="Population, total")
.label(
x="Log GDP per Capita",
y="Log Under-5 Mortality",
title="Income and Child Mortality",
)
.theme({**style.library["seaborn-v0_8-whitegrid"]})
)
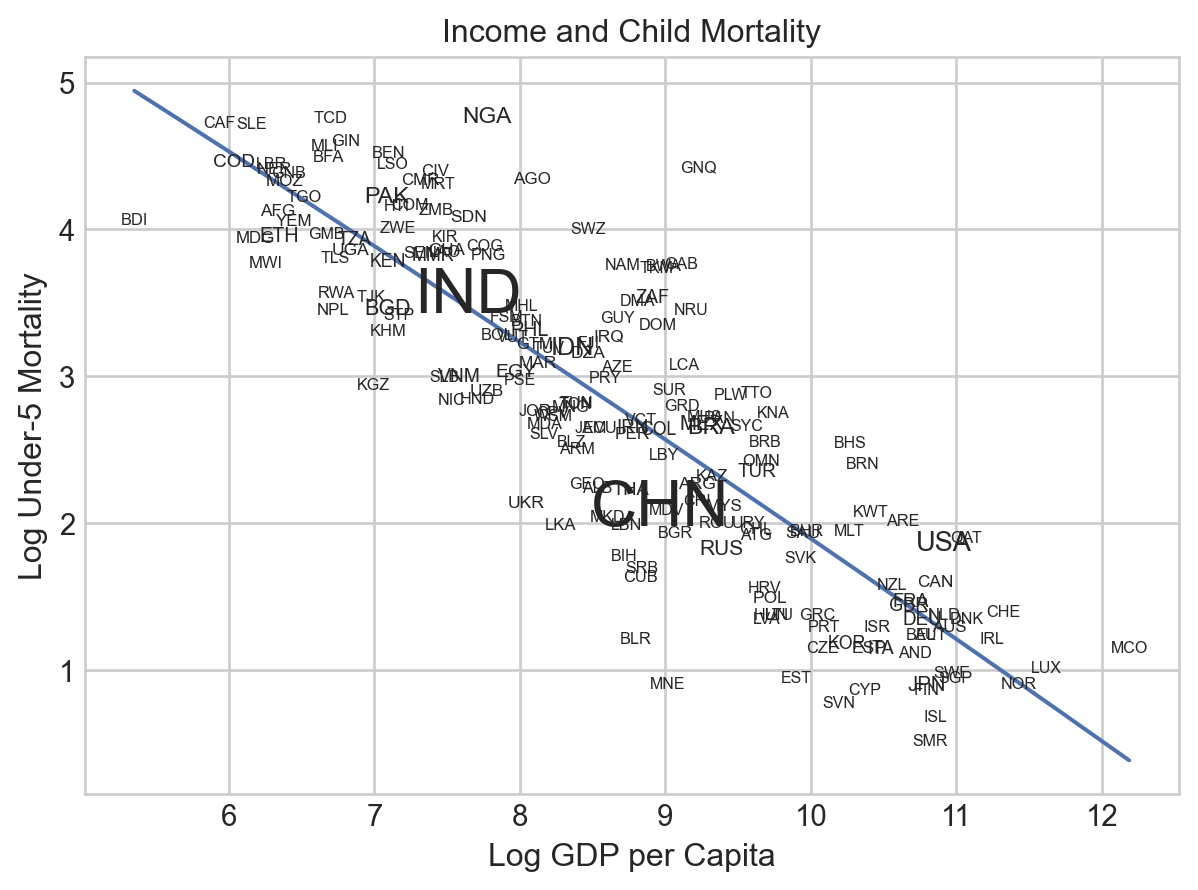
Themes are actually just dictionary is full of a bunch of matplotlib plot specifications, so it’s also very easy to modify an existing theme if you want to make it fit your preferences more. For example, if you like the theme used above but you would prefer not to have axis lines and want a different font, you can just update the theme dictionary:
updated_theme = style.library["seaborn-v0_8-whitegrid"] | {
"axes.spines.right": False,
"axes.spines.top": False,
"axes.grid": False,
}
(
so.Plot(world, x="log_gdp_per_cap", y="log_under5_mortality_rate")
.add(so.Line(), so.PolyFit())
.add(so.Text(), text="Country Code", fontsize="Population, total")
.label(
x="Log GDP per Capita",
y="Log Under-5 Mortality",
title="Income and Child Mortality",
)
.theme({**updated_theme})
)
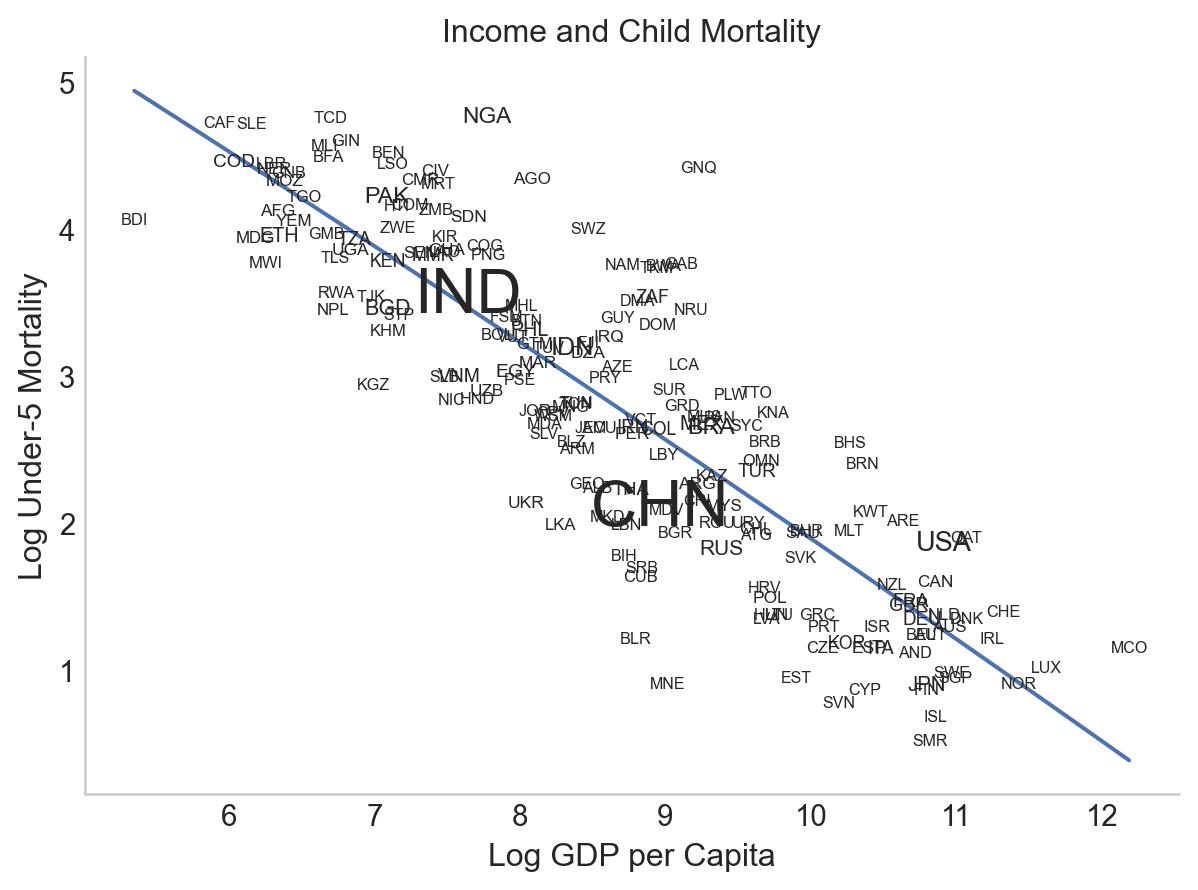
You can find a full list of all available specification keywords here. It’s not the most accessible thing in the world, but thankfully it’s easy to guess and check. :)
Converting and Editing a Seaborn Objects Plot as Matplotlib Axes#
One of the best features of Seaborn Objects is that is you find seaborn.objects won’t do something you want, you can always convert your seaborn.objects Plot as a matplotlib axes. To do so, simply create a pyplot figure, then use the .on().show() methods to add your seaborn Plot to that figures. You can then access the single axes object in that figure with f.axes[0] and edit the way you would any pyplot axes object.
(you do seem to need the .show() after the .on()!)
Note that you won’t always see the result in the window (as below) if you’re working with a Jupyter Notebook or other interactive visualization tool, but the saved image will have all relevant edits.
import matplotlib.pyplot as plt
f = plt.figure()
(
so.Plot(
world,
x="log_gdp_per_cap",
y="log_under5_mortality_rate",
)
.add(so.Dot())
.on(f)
.show()
)
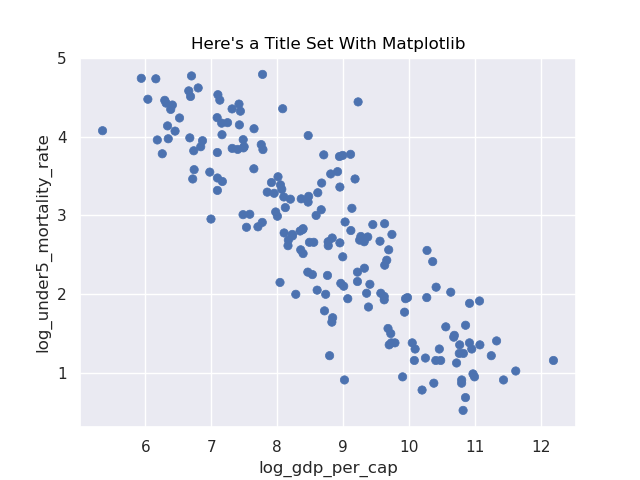
ax = f.axes[0]
ax.set_title("Here's a Title Set With Matplotlib")
f.savefig("img/seaborn_w_matplotlib_title.png")
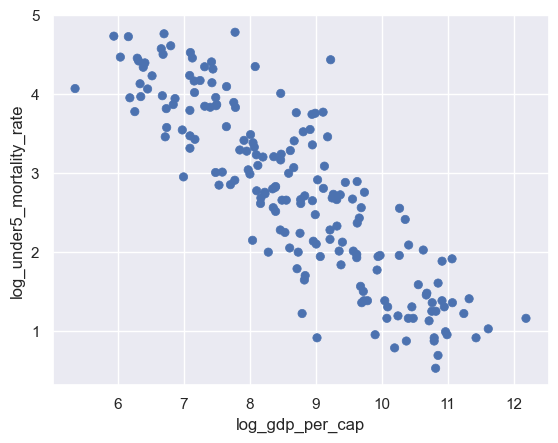
Here’s what I see when I load the saved image:
Getting help with seaborn.objects#
Because the seaborn object’s interface was only released in 2022, it is still evolving, and while the documentation is good it is not complete. Nevertheless, as we will discuss later, because one can always fall back on matplotlib (which is incredibly well documented) if one has need, it nevertheless feels like a safe choice of plotting libraries.
As of late 2023, there are three places to go to get help:
The official seaborn.objects tutorial page. some great examples of the various things you can do with seaborn.objects, including some things we don’t cover here like faceting.
The official seaborn.objects API page. A list of all the different types of Marks and their associated documentation.
Stackoverflow! Make sure to tag your question with the
seaborntag so will gets noticed by the right people. Before you post on stackoverflow, however, make sure to read up on how to most effectively get good help online.